안녕하세요! 이번에는 OpenSSL 1에서 3 버전으로 변경하는 과정에서 Python 코드에서 발생할 수 있는 "unsafe legacy renegotiation disabled" 오류에 대해 알아보겠습니다. OpenSSL 버전을 업그레이드하면서 이 오류가 발생하는 경우가 있습니다. 이 블로그에서는 해당 오류를 해결하기 위해 /usr/lib/ssl/openssl.conf 파일에 추가해야 할 설정에 대해 알려드리겠습니다.
문제 해결: "/usr/lib/ssl/openssl.conf" 파일 수정
1. 먼저, 터미널을 열고 아래의 명령어를 실행하여 "/usr/lib/ssl/openssl.conf" 파일을 엽니다:
안녕하세요! 이번에는 Linux에서 프로세스를 종료하는 방법에 대해 알아보겠습니다. Linux에서 프로세스를 제어하고 관리하는 것은 중요한 작업 중 하나입니다. 여러분은 시스템에 실행 중인 프로세스를 종료하거나 문제가 있는 프로세스를 강제 종료해야 할 때가 있을 것입니다. 이 블로그에서는 kill 명령어와 pkill 명령어를 사용하여 프로세스를 종료하는 방법을 알려드리겠습니다.
kill 명령어를 사용하여 프로세스 종료하기
kill 명령어는 특정 프로세스나 프로세스 그룹에 시그널을 보내 프로세스를 종료하는 데 사용됩니다. 기본적인 사용법은 다음과 같습니다:
kill [옵션] <프로세스 ID>
옵션: 명령어의 동작을 제어하는 옵션을 지정할 수 있습니다. 자주 사용되는 옵션으로는 -9 (SIGKILL 시그널을 보내 프로세스를 강제 종료)이 있습니다.
Python에서 모듈을 import할 때, 시스템은 해당 모듈의 위치를 찾기 위해 경로를 검색합니다. 경로를 올바르게 설정하지 않으면 모듈을 찾을 수 없는 오류가 발생할 수 있습니다. 이러한 상황에서는 모듈의 경로를 확인하고 필요한 경로를 추가하는 방법을 알아야 합니다. 이번 글에서는 이와 관련된 방법에 대해 알아보겠습니다.
1. 모듈 경로 확인하기
Python에서 모듈의 경로를 확인하는 방법은 sys 모듈의 path 속성을 이용하는 것입니다. sys.path는 리스트 형태로 현재 사용 중인 Python 인터프리터가 모듈을 검색하는 경로들을 담고 있습니다. 이를 출력하여 확인해볼 수 있습니다. 아래는 이를 수행하는 예제 코드입니다:
import sys
print(sys.path)
위 코드를 실행하면 Python 인터프리터가 사용하는 경로들이 출력됩니다. 이를 통해 모듈을 검색하는 기본 경로를 확인할 수 있습니다.
2. 경로 추가하기
모듈을 검색하는 경로에 직접 경로를 추가하려면 sys.path 리스트에 경로를 추가하면 됩니다. sys.path 리스트의 첫 번째 요소로 현재 디렉토리가 자동으로 포함되어 있습니다. 그 외에 추가로 경로를 추가해야 하는 경우에는 다음과 같이 수행할 수 있습니다:
import sys
# 경로 추가
sys.path.append("/path/to/module")
# 경로 확인
print(sys.path)
위 예제 코드에서 "/path/to/module" 부분은 실제 모듈이 위치한 디렉토리 경로로 대체되어야 합니다. 경로를 추가한 후에는 해당 경로에서 모듈을 검색할 수 있게 됩니다.
3. 특정 기능만 가져오기
만약 모듈에서 특정한 함수나 변수만 사용하고 싶다면, import문을 다음과 같이 작성할 수 있습니다:
from 모듈명 import 기능명
위 예제에서 모듈명은 가져올 모듈의 이름이고, 기능명은 가져올 함수나 변수의 이름입니다. 예를 들어, math 모듈에서 sqrt 함수만 사용하고 싶다면 다음과 같이 작성할 수 있습니다:
from math import sqrt
이제 sqrt 함수를 직접 사용할 수 있습니다.
3. 모듈에 별칭(alias) 붙이기
가끔 모듈의 이름이 길거나 중복되는 경우가 있습니다. 이럴 때는 모듈에 별칭(alias)을 붙여 사용할 수 있습니다. import문을 다음과 같이 작성하면 모듈에 별칭을 지정할 수 있습니다:
import 모듈명 as 별칭
위 예제에서 모듈명은 가져올 모듈의 이름이고, 별칭은 모듈에 지정할 별칭입니다. 예를 들어, numpy 모듈을 가져올 때 np라는 별칭을 사용하고 싶다면 다음과 같이 작성할 수 있습니다:
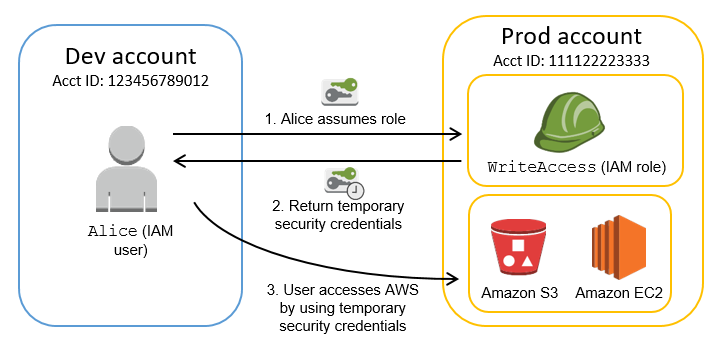
Splunk SOAR(이하 Phantom 으로 지칭) 에서 제공하는 AWS 관련 app을 보면 아래와 같이 2가지 방법으로 Phantom 과 AWS를 연결할 수 있다.
첫번째, Access Key / Secret Key 를 입력하는 방법.
두번재, EC2에서 현재 Phantom 을 실행할때 연결된 role 을 사용하는 방법.
위 두가지 방법 중 두번째 방법을 보면 체크 박스에 체크를 하는것만으로도 AWS App 의 Test connectivity 가 정상적으로 Pass가 되는걸 볼수가 있다. (Phantom이 EC2에 실행이 되어야 하고 role을 사용해야 함.) 어떻게 key 또는 ID / PWD가 없이 연결이 되는거지? 라는 의문이 들었다. 해당 의문에 대해서는 다음과 같은 사이트에서 이해할 수 있었다. (https://cloudguardians.medium.com/ec2-instance-metadata-보안-edd23f56b64c)
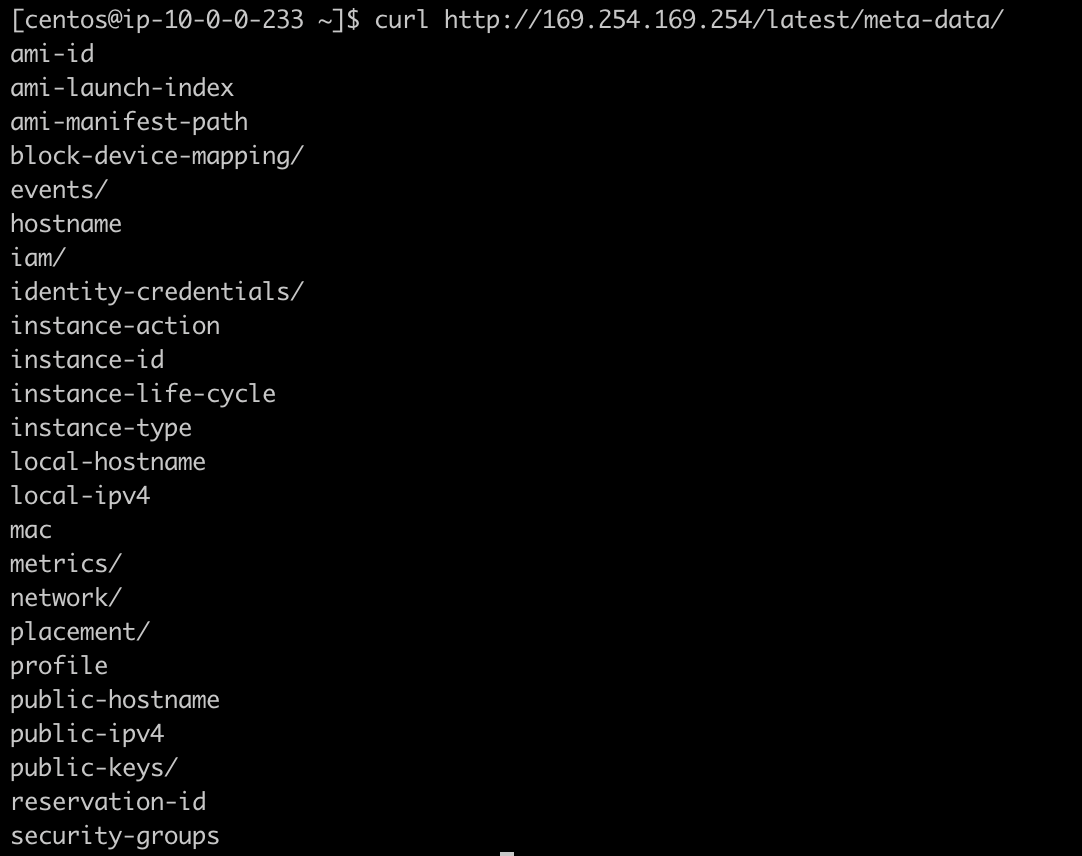
메타데이터를 이용해 EC2에 대한 정보를 가져올수가 있는데 아래와 같이 curl을 던지면 사용 가능한 meta-data정보 리스트를 확인해볼수 있다.
/iam/security-credentials/ 정보를 체크해보면
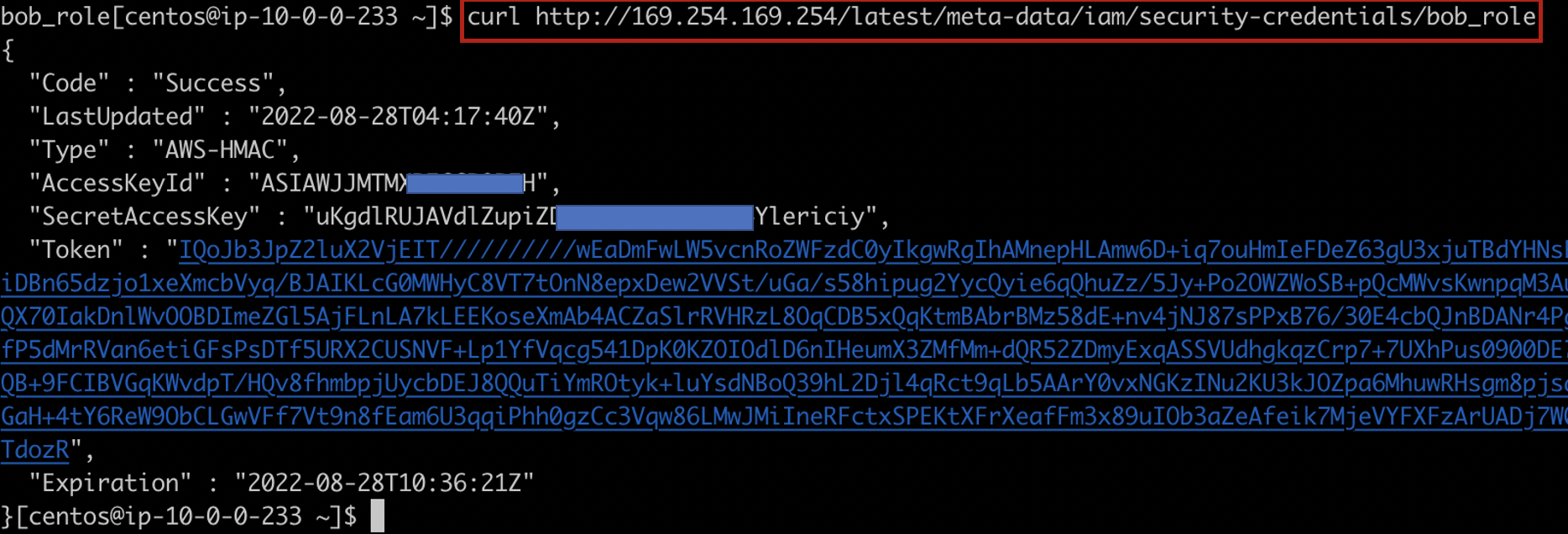
해당 Phantom이 설치된 EC2 인스턴스는 bob_role이라는 role을 사용하고 있다는걸 알수 있다. bob_role 를 통해 임시보안자격증명을 하려면 아래와 같이 임시로 쓸수 있는 key와 만료시간을 전달받을 수가 있다.
임시로 쓰는 키지만…다 보여드리기 기분이 좀 그래서 가림..ㅎㅎ 다시 돌아와 Phantom app 에서 use_role을 체크한다면 아래와 같은 boto3를 이용한 소스가 실행되 key 값을 받게된다.
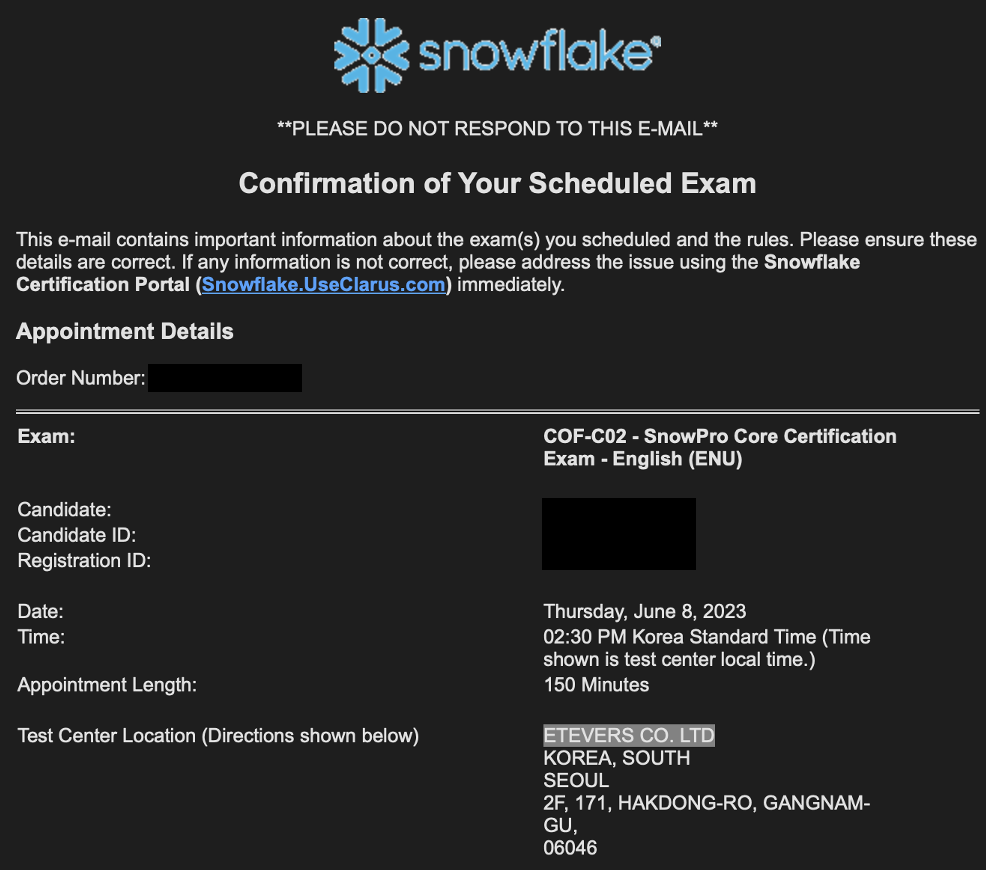
안녕하세요! 여러분에게 저의 최근 'snowpro core certification' 시험 경험을 소개하려 합니다.
Pearson VUE를 통해 Snowflake Core 시험은 온라인 또는 오프라인으로 응시할 수 있습니다. 저는 온라인 시험의 경우 외국인 감독관이 확인하는 것으로 들었기에(확실한 정보는 아니었습니다만), 선호하는 오프라인 시험을 선택했습니다. 지난주인 6월 8일, 목요일에 학동에 위치한 ETEVERS에서 시험을 보았습니다.
결제를 하고 이메일을 꼭 확인해야 한다.
시험은 총 100문제로 구성되어 있으며, 공식적인 시험 시간은 115분입니다. 하지만, 비영어권 국가에서 시험을 보는 경우 추가로 30분이 주어져 총 150분 동안 시험을 볼 수 있습니다. 시험 응시료는 175달러로, 약 20만원이라고 할 수 있습니다. (당연히, 한번에 합격해야겠죠..!)
선택 가능한 언어는 영어와 일본어입니다. 아쉽게도 한국어는 제공되지 않습니다. 시험은 총 1000점 만점으로, 750점 이상을 얻어야 합격입니다. 다행히, 저는 한번에 시험에 합격했습니다! 시험을 마치고 나면 모니터에 바로 합격 여부가 나타나고, 시험장을 나와 프론트로 가면 합격 여부 및 점수가 적힌 종이를 받을 수 있습니다.
공부는 처음에는 dumpkorea에서 dump를 구입했습니다. 하지만 첫 문제부터 답이 틀려서 큰 충격을 받았고 거의 50% 이상이 틀리더군요. 이런 상황에서 dump에서 틀린 답을 외울지, examtopics에서 투표로 선택된 답을 외울지 많은 고민을 했습니다. 결국, 시험에 떨어지더라도 올바른 지식을 습득하는 것이 더 중요하다는 결론을 내리고, 총 260개의 문제 중 각각 examtopics에서 찾아 정답을 고쳐 외웠습니다.
그런데 examtopics에 들어가서 전체 문제를 보니 총 650개의 문제가 있고, dump에는 없는 문제가 많았습니다. 이에 dump를 외우는 것을 중단하고, examtopics를 결제한 후에 examtopics의 문제를 3일 동안 미친 듯이 외웠습니다. 하루에 약 200개씩 외우고, 당일에는 전체 문제를 한 번씩 다시 보는 방법을 사용했습니다.
시험에서는 650개의 문제 이외에도 전혀 처음 보는 문제가 몇 개 나와서 당황스러웠지만 차근차근 풀어보니, 그리 많은 문제를 틀리지 않고 넉넉한 점수로 합격할 수 있었습니다. examtopics에서 특히 400~638 사이의 최근 문제가 비중이 높게 나온 것 같습니다.
국내에서 Snowflake에 관심 있는 사람이 얼마나 될지는 모르겠지만, 파트너나 사용자라면 이론적인 측면에서 Snowflake Core 자격증 공부를 하고, 실습은 Hand-on badge 1~5를 해보는 것이 큰 도움이 될 것 같습니다. 또, 만약 MSSQL 혹은 MySQL과 같은 SQL을 사용해본 경험이 있다면, 이해하기 더 쉬울 것입니다.
AWS는 클라우드 기술 서비스를 제공하고 있습니다. AWS의 서비스를 사용하면 클라우드에서 간단하고 안전하게 애플리케이션을 실행할 수 있습니다. 그 중 AWS STS와 Assume Role에 대해 알아보겠습니다.
AWS STS란 무엇인가요?
AWS STS(Security Token Service)는 AWS에서 보안 토큰을 생성하는 서비스입니다. AWS STS를 사용하면 AWS IAM 사용자나 AWS 외부 자격 증명을 사용하여 액세스 권한을 부여할 수 있습니다.
AWS STS의 장점
AWS STS는 일시적인 보안 자격 증명을 생성하므로 보안성이 높습니다.
IAM 사용자 또는 AWS 외부 자격 증명으로 AWS 리소스에 대한 액세스 권한을 제한할 수 있습니다.
AWS STS를 사용하면 AWS 리소스에 대한 권한을 부여하는 방법을 보다 더 유연하게 조정할 수 있습니다.
Assume Role이란 무엇인가요?
Assume Role은 AWS IAM에서 지원하는 기능 중 하나입니다. AWS IAM에서 Assume Role을 사용하면 IAM 사용자 또는 AWS 외부 자격 증명으로 다른 AWS 계정 또는 리소스에 액세스할 수 있습니다.
Assume Role의 장점
Assume Role을 사용하면 하나의 IAM 사용자 또는 외부 자격 증명을 여러 AWS 계정 또는 리소스에 대해 공유할 수 있습니다.
Assume Role을 사용하여 AWS 계정 또는 리소스에 대한 액세스 권한을 조정할 수 있습니다.
Assume Role을 사용하면 권한 부여를 간편하게 할 수 있습니다.
AWS STS와 Assume Role을 사용하는 방법
AWS STS와 Assume Role을 사용하는 방법은 다음과 같습니다.
AWS STS를 사용하여 일시적인 자격 증명을 생성합니다.
생성된 일시적인 자격 증명으로 Assume Role을 호출합니다.
Assume Role이 호출되면, 해당하는 AWS 리소스에 대한 액세스 권한을 부여받게 됩니다.
AWS STS와 Assume Role을 사용하는 이유
AWS STS와 Assume Role을 사용하는 이유는 다음과 같습니다.
IAM 사용자나 외부 자격 증명으로 AWS 리소스에 대한 액세스 권한을 부여할 수 있습니다.
AWS 리소스에 대한 권한을 더욱 세밀하게 제어할 수 있습니다.
일시적인 자격 증명을 사용하기 때문에 보안성이 높습니다.
AWS STS와 Assume Role을 함께 사용하는 경우
AWS STS와 Assume Role을 함께 사용하면 보다 유연하게 AWS 리소스에 대한 권한을 관리할 수 있습니다. 다음은 AWS STS와 Assume Role을 함께 사용하는 경우입니다.
AWS STS를 사용하여 일시적인 자격 증명을 생성합니다.
Assume Role을 호출하고 생성된 일시적인 자격 증명을 사용하여 IAM 사용자나 외부 자격 증명으로 다른 AWS 계정 또는 리소스에 액세스합니다.
AWS STS와 Assume Role의 보안
AWS STS와 Assume Role은 일시적인 자격 증명을 사용하여 AWS 리소스에 대한 액세스 권한을 부여합니다. 이러한 일시적인 자격 증명은 만료되므로 보안성이 높습니다. 또한 AWS STS와 Assume Role을 사용하면 권한 부여를 보다 세밀하게 제어할 수 있으므로 보안성이 더욱 강화됩니다.
AWS STS와 Assume Role의 사용 사례
AWS STS와 Assume Role은 다양한 사용 사례를 가지고 있습니다. 예를 들어, 다음과 같은 경우에 AWS STS와 Assume Role을 사용할 수 있습니다.
여러 AWS 계정 간의 권한 부여
AWS 리소스에 대한 세밀한 권한 부여
일시적인 자격 증명을 사용하여 보안성 강화
결론
AWS STS와 Assume Role은 AWS에서 제공하는 보안 기능 중 하나입니다. 이러한 기능을 사용하면 AWS 리소스에 대한 액세스 권한을 보다 유연하게 관리할 수 있습니다. 또한 보안성을 강화하기 위한 일시적인 자격 증명을 사용하여 권한 부여를 할 수 있습니다.
FAQ
AWS STS와 Assume Role을 사용하는 이유는 무엇인가요?
AWS STS와 Assume Role을 사용하면 IAM 사용자나 외부 자격 증명으로 AWS 리소스에 대한 액세스 권한을 부여할 수 있습니다.
AWS 리소스에 대한 권한을 더욱 세밀하게 제어할 수 있습니다.
일시적인 자격 증명을 사용하기 때문에 보안성이 높습니다.
AWS STS와 Assume Role을 함께 사용하는 경우는 어떤 경우인가요?
AWS STS와 Assume Role을 함께 사용하면 보다 유연하게 AWS 리소스에 대한 권한을 관리할 수 있습니다.
AWS STS와 Assume Role을 사용하면 어떤 보안 이점이 있나요?
AWS STS와 Assume Role을 사용하면 일시적인 자격 증명을 사용하여 AWS 리소스에 대한 액세스 권한을 부여합니다.
이러한 일시적인 자격 증명은 만료되므로 보안성이 높습니다.
또한 AWS STS와 Assume Role을 사용하면 권한 부여를 보다 세밀하게 제어할 수 있으므로 보안성이 더욱 강화됩니다.
AWS STS와 Assume Role의 사용 사례는 어떤 것이 있나요?
여러 AWS 계정 간의 권한 부여
AWS 리소스에 대한 세밀한 권한 부여
일시적인 자격 증명을 사용하여 보안성 강화
AWS STS와 Assume Role은 보안성을 어떻게 강화하나요?
일시적인 자격 증명을 사용하여 AWS 리소스에 대한 액세스 권한을 부여합니다.
권한 부여를 보다 세밀하게 제어할 수 있습니다.
AWS STS와 Assume Role을 사용하는 방법은 어떻게 되나요?
AWS STS를 사용하여 일시적인 자격 증명을 생성합니다.
생성된 일시적인 자격 증명으로 Assume Role을 호출합니다.
Assume Role이 호출되면, 해당하는 AWS 리소스에 대한 액세스 권한을 부여받게 됩니다.
AWS STS와 Assume Role은 어떤 기능을 제공하나요?
AWS STS는 AWS에서 보안 토큰을 생성하는 서비스입니다.
Assume Role은 IAM 사용자나 외부 자격 증명으로 다른 AWS 계정 또는 리소스에 액세스할 수 있는 기능입니다.
AWS STS와 Assume Role을 사용하여 어떤 문제를 해결할 수 있나요?
AWS 리소스에 대한 액세스 권한을 보다 세밀하게 제어할 수 있습니다.
하나의 IAM 사용자 또는 외부 자격 증명을 여러 AWS 계정 또는 리소스에 대해 공유할 수 있습니다.
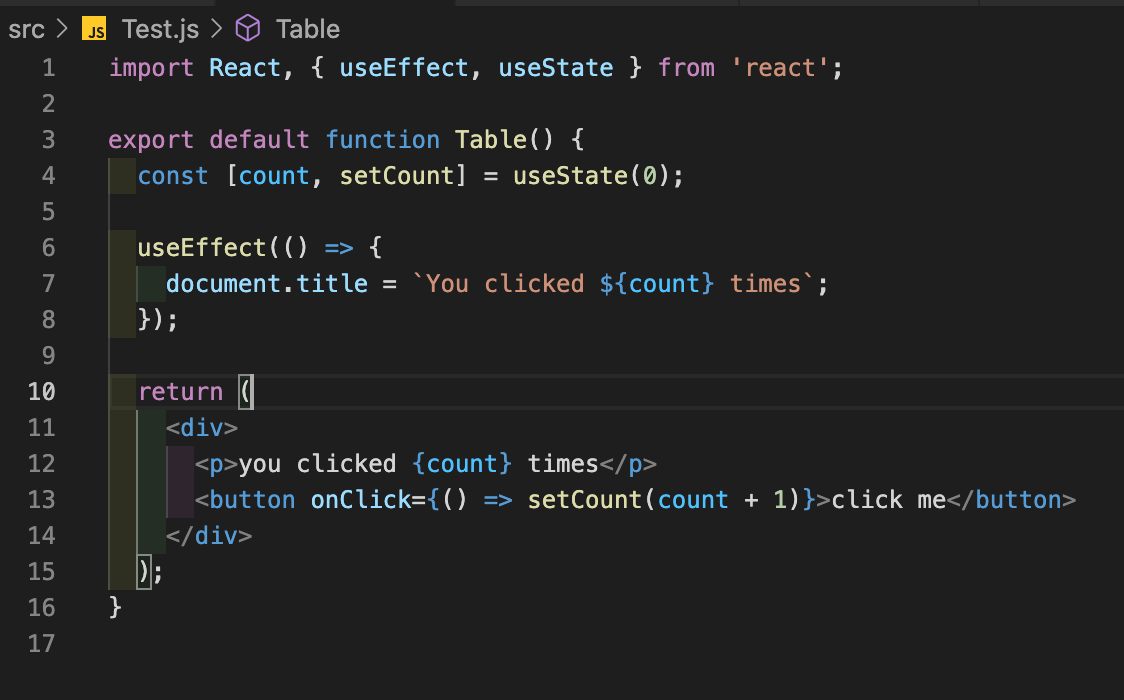
React는 UI를 구축하기 위한 JavaScript 라이브러리입니다. useEffect는 React의 라이프사이클 메소드 중 하나로, 컴포넌트가 렌더링될 때마다 특정한 작업을 수행할 수 있도록 해줍니다. 이번 글에서는 React useEffect에 대해 예제와 함께 자세히 설명해보겠습니다.
React의 라이프사이클 메소드
React에서는 라이프사이클 메소드를 사용하여 컴포넌트의 생명주기를 관리합니다. 이 메소드들은 컴포넌트가 생성되고, 업데이트되고, 제거될 때 자동으로 호출됩니다. useEffect는 이러한 라이프사이클 메소드 중 하나이며, 컴포넌트가 렌더링될 때마다 실행됩니다.
useEffect의 기본 사용법
useEffect는 두 개의 매개변수를 받습니다. 첫 번째 매개변수는 함수이며, 두 번째 매개변수는 배열입니다. 함수는 컴포넌트가 렌더링될 때마다 실행되며, 배열에는 useEffect가 의존하는 변수들을 넣습니다.
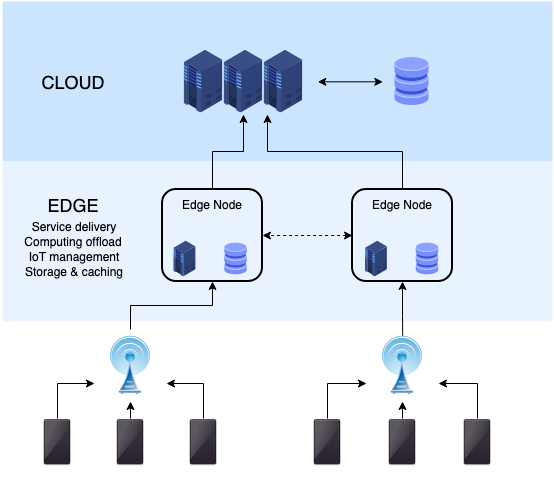
엣지 컴퓨팅(Edge Computing)과 CDN(Content Delivery Network)은 둘 다 웹 성능 최적화를 위한 기술이지만, 각각 다른 방식으로 동작합니다. 이번 글에서는 두 기술의 차이점과 장단점을 알아보도록 하겠습니다.
엣지 컴퓨팅(Edge Computing)
엣지 컴퓨팅은 서버와 클라이언트 사이의 거리를 줄여 지연 시간을 최소화하고 대역폭 사용량을 최적화하기 위한 기술입니다. 일반적으로, 엣지 컴퓨팅은 클라우드 서비스와 달리, 지리적으로 분산된 많은 디바이스에 데이터 처리 능력을 제공하는 것을 목적으로 합니다.
예를 들어, 머신러닝 모델의 경우 클라우드에서 모델을 학습시키고, 학습된 모델을 디바이스에 배포해 엣지에서 실시간으로 추론 작업을 수행하도록 할 수 있습니다. 이렇게 함으로써, 대규모 데이터를 전송하고 분석하는 데 필요한 대역폭을 줄이고, 실시간 응답 시간을 단축시킬 수 있습니다.
CDN(Content Delivery Network)
CDN은 인터넷에서 웹 사이트나 앱의 콘텐츠를 전송하는 데 사용되는 분산 네트워크입니다. CDN은 캐싱과 프록시 서버를 사용하여, 사용자가 해당 콘텐츠에 대한 요청을 할 때, 가장 가까운 서버에서 해당 콘텐츠를 전송하도록 합니다. 이를 통해, 지연 시간과 대역폭을 줄이고, 빠른 웹 사이트 로딩 속도를 제공합니다.
예를 들어, 미국 서부에 위치한 사용자가 한국에 있는 서버에서 호스팅되는 웹 사이트에 접속하는 경우, CDN을 사용하면 미국 서부에서 가장 가까운 서버에서 콘텐츠를 전송하도록 할 수 있습니다. 이렇게 함으로써, 사용자가 웹 사이트를 더 빠르게 로딩할 수 있습니다.
엣지 컴퓨팅과 CDN의 차이점
두 기술은 웹 성능 최적화를 위해 사용됩니다. 그러나 엣지 컴퓨팅은 디바이스와 서버 사이의 거리를 줄이고 대역폭을 최적화하기 위해 사용되는 반면, CDN은 인터넷에서 콘텐츠 전송을 최적화하기 위해 사용됩니다.
그러나 엣지 컴퓨팅은 디바이스와 서버 사이의 거리를 줄이고 대역폭을 최적화하기 위해 사용되는 반면, CDN은 인터넷에서 콘텐츠 전송을 최적화하기 위해 사용됩니다.
엣지 컴퓨팅은 데이터 처리와 분석이 필요한 많은 디바이스가 분산되어 있을 때 특히 유용합니다. 예를 들어, 자율주행 자동차나 스마트 홈 기기는 데이터를 실시간으로 처리해야 하므로 엣지 컴퓨팅을 사용합니다. 또한, 인터넷 연결이 불안정하거나 제한적인 디바이스에서도 엣지 컴퓨팅을 사용할 수 있습니다.
반면에, CDN은 전 세계적으로 사용되는 웹 사이트나 앱에서 트래픽을 최적화하는 데 유용합니다. CDN은 콘텐츠를 캐싱하고 프록시 서버를 사용하여 콘텐츠 전송을 최적화하기 때문에, 전 세계의 사용자들이 웹 사이트나 앱에서 더 빠르게 콘텐츠를 로딩할 수 있습니다.
따라서, 엣지 컴퓨팅은 디바이스와 서버 사이의 거리를 최적화하고 대역폭을 줄이기 위해 사용되는 반면, CDN은 인터넷에서 콘텐츠 전송을 최적화하기 위해 사용됩니다. 두 기술은 서로 보완적이며, 애플리케이션의 특성에 따라 적절한 기술을 선택하여 사용해야 합니다.
엣지 컴퓨팅과 CDN
엣지 컴퓨팅(Edge Computing)과 CDN(Content Delivery Network)은 둘 다 웹 성능 최적화를 위한 기술이지만, 각각 다른 방식으로 동작합니다. 이번 글에서는 두 기술의 차이점과 장단점을 알아보도록 하겠습니다.
엣지 컴퓨팅(Edge Computing)
엣지 컴퓨팅은 서버와 클라이언트 사이의 거리를 줄여 지연 시간을 최소화하고 대역폭 사용량을 최적화하기 위한 기술입니다. 일반적으로, 엣지 컴퓨팅은 클라우드 서비스와 달리, 지리적으로 분산된 많은 디바이스에 데이터 처리 능력을 제공하는 것을 목적으로 합니다.
예를 들어, 머신러닝 모델의 경우 클라우드에서 모델을 학습시키고, 학습된 모델을 디바이스에 배포해 엣지에서 실시간으로 추론 작업을 수행하도록 할 수 있습니다. 이렇게 함으로써, 대규모 데이터를 전송하고 분석하는 데 필요한 대역폭을 줄이고, 실시간 응답 시간을 단축시킬 수 있습니다.
CDN(Content Delivery Network)
CDN은 인터넷에서 웹 사이트나 앱의 콘텐츠를 전송하는 데 사용되는 분산 네트워크입니다. CDN은 캐싱과 프록시 서버를 사용하여, 사용자가 해당 콘텐츠에 대한 요청을 할 때, 가장 가까운 서버에서 해당 콘텐츠를 전송하도록 합니다. 이를 통해, 지연 시간과 대역폭을 줄이고, 빠른 웹 사이트 로딩 속도를 제공합니다.
예를 들어, 미국 서부에 위치한 사용자가 한국에 있는 서버에서 호스팅되는 웹 사이트에 접속하는 경우, CDN을 사용하면 미국 서부에서 가장 가까운 서버에서 콘텐츠를 전송하도록 할 수 있습니다. 이렇게 함으로써, 사용자가 웹 사이트를 더 빠르게 로딩할 수 있습니다.
엣지 컴퓨팅과 CDN의 차이점
두 기술은 웹 성능 최적화를 위해 사용됩니다. 그러나 엣지 컴퓨팅은 디바이스와 서버 사이의 거리를 줄이고 대역폭을 최적화하기 위해 사용되는 반면, CDN은 인터넷에서 콘텐츠 전송을 최적화하기 위해 사용됩니다.
그러나 엣지 컴퓨팅은 디바이스와 서버 사이의 거리를 줄이고 대역폭을 최적화하기 위해 사용되는 반면, CDN은 인터넷에서 콘텐츠 전송을 최적화하기 위해 사용됩니다.
엣지 컴퓨팅은 데이터 처리와 분석이 필요한 많은 디바이스가 분산되어 있을 때 특히 유용합니다. 예를 들어, 자율주행 자동차나 스마트 홈 기기는 데이터를 실시간으로 처리해야 하므로 엣지 컴퓨팅을 사용합니다. 또한, 인터넷 연결이 불안정하거나 제한적인 디바이스에서도 엣지 컴퓨팅을 사용할 수 있습니다.
반면에, CDN은 전 세계적으로 사용되는 웹 사이트나 앱에서 트래픽을 최적화하는 데 유용합니다. CDN은 콘텐츠를 캐싱하고 프록시 서버를 사용하여 콘텐츠 전송을 최적화하기 때문에, 전 세계의 사용자들이 웹 사이트나 앱에서 더 빠르게 콘텐츠를 로딩할 수 있습니다.
따라서, 엣지 컴퓨팅은 디바이스와 서버 사이의 거리를 최적화하고 대역폭을 줄이기 위해 사용되는 반면, CDN은 인터넷에서 콘텐츠 전송을 최적화하기 위해 사용됩니다. 두 기술은 서로 보완적이며, 애플리케이션의 특성에 따라 적절한 기술을 선택하여 사용해야 합니다.
이 문제는 부동소수점 숫자를 표현하는 방식 때문에 발생합니다. 컴퓨터에서 부동소수점 숫자는 이진수로 표현됩니다. 이진수로 표현된 소수는 종종 무한 소수가 될 수 있기 때문에, 컴퓨터는 이진수에서 유한한 비트 수만큼만 표현합니다.
1.1과 0.1은 이진수로 정확히 표현할 수 없는 무한 소수입니다. 따라서 컴퓨터에서 이 값들은 근사치로 표현됩니다.
따라서 **1.1 + 0.1**은 컴퓨터에서는 **1.2000000000000002**와 같은 값을 가질 수 있습니다. 이는 **1.2**와 같지 않으므로, **1.1 + 0.1 == 1.2**가 False가 됩니다.
해결 방법
이러한 문제를 해결하기 위해, 부동소수점 숫자를 비교할 때는 약간의 오차를 허용해야 합니다. 즉, "1.1 + 0.1이 1.2와 거의 같다"라는 식으로 비교해야 합니다. 일반적으로는 다음과 같은 방법을 사용합니다.
import math
tolerance = 1e-10
if math.isclose(1.1 + 0.1, 1.2, rel_tol=tolerance):
print("approximately equal")
else:
print("not approximately equal")
위 코드는 math.isclose()함수를 사용하여 1.1 + 0.1과 1.2가 "거의 같은" 값인지 확인합니다. 이 함수는 두 숫자가 동일하거나(rel_tol=0), 혹은 상대 오차(rel_tol) 혹은 절대 오차(abs_tol) 안에 있는 경우 True를 반환합니다. 위 코드에서는 상대 오차를 사용하여 비교합니다.